Companion webpage to our CVPR 2021 publication. Asterisks denote equal contribution.
Abstract
Over the last few years, we have witnessed tremendous progress on many subtasks of autonomous driving, including perception, motion forecasting, and motion planning. However, these systems often assume that the car is accurately localized against a high-definition map.
In this paper we question this assumption, and investigate the issues that arise in state-of-the-art autonomy stacks under localization error. Based on our observations, we design a system that jointly performs perception, prediction, and localization. Our architecture is able to reuse computation between both tasks, and is thus able to correct localization errors efficiently. We show experiments on a large-scale autonomy dataset, demonstrating the efficiency and accuracy of our proposed approach.
Joint Localization, Perception, and Prediction
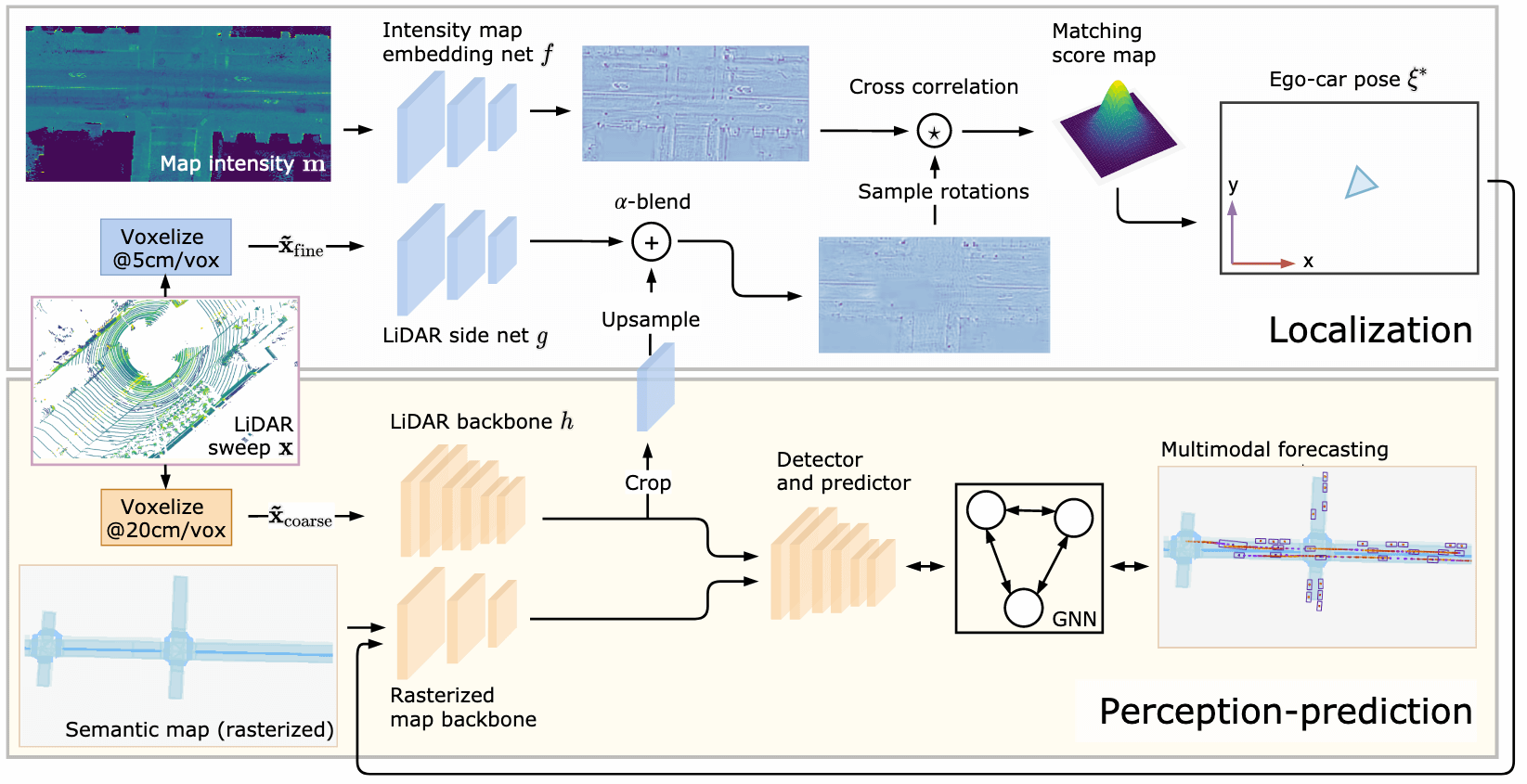 |
|---|
| Proposed Architecture. We propose a joint architecture for localization, perception, and prediction (LP2) from LiDAR data. Please refer to the video above or our paper for additional information. |
BibTeX
@inproceedings{phillips2021multitask,
title = {Deep Multi-Task Learning for Joint Localization,
Perception, and Prediction},
author={Phillips, John and Martinez, Julieta
and B{\^a}rsan, Ioan Andrei
and Casas, Sergio and Sadat, Abbas
and Urtasun, Raquel},
booktitle = {The {IEEE} Conference on Computer Vision
and Pattern Recognition ({CVPR})},
month = jun,
year = {2021},
url = {https://arxiv.org/abs/2101.06720}
}
